LLM Production
Deploying LLMs in a single Machine
In this post, I will share my experience deploying LLMs in production. I will cover the challenges I faced, the solutions I found, and the lessons I learned along the way.
- first I managed to find a gpu from runpod to experience one complete conversation(multi-inferences).
- now I know that if you want to deploy this in production, you not only need multiple gpu like the one
I’m using in the following writing, you also need a system to help you manage resources (i.e. Kubernetes).
2.1. so they have the solution called
vllm production-stackGot to find a cluster with powerful GPUs, OR I could just deploy the stack, since now I’ve experienced model inference. But it will be hard to tell if I deploy it successfully or not… ~(- <_ -)>
-
resource for personal: runpod.io
-
for similar service, you can use Lambda(not AWS), GCP, Azure, etc.
If using AKS: Setup automated deployments to the AKS cluster ( optional )
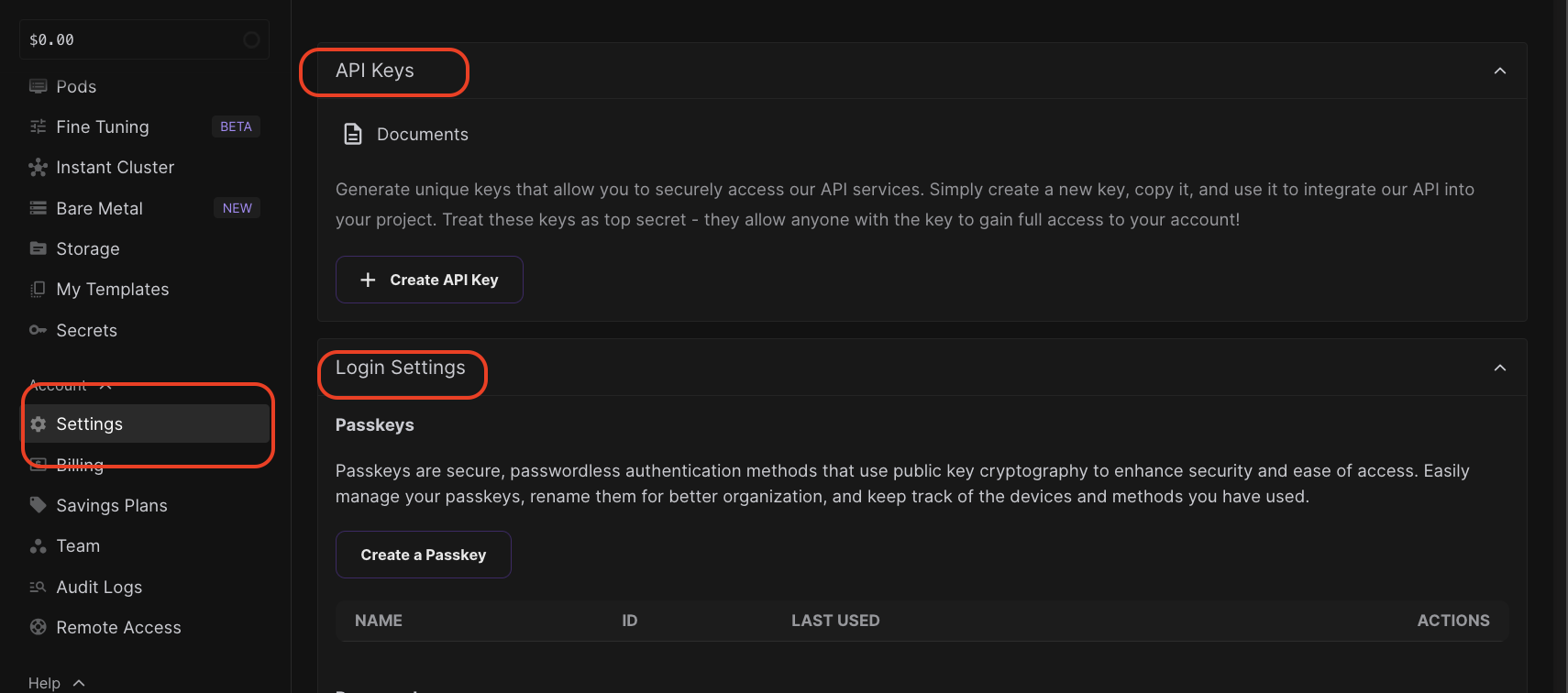
Create a runpod.io account to get cloud GPU access (API access)
- You can use API keys for project access
- Passkey for secure passwordless authentication access
- How to choose the GPU
- It depends on your needs, you can just spin up a cheapest choice on runpod, which is enough for me to run the model
Create ssh keys to for remote access (Virtual Machine access)
-
Runpod just a service to provide you powerful GPUs
-
create a ssh-key pair
ssh-keygen -t rsa -b 4096 -C "This is a comment"
- Paste the public key to the runpod.io’s ssh public key at
Account > Settings > SSH Public Keys
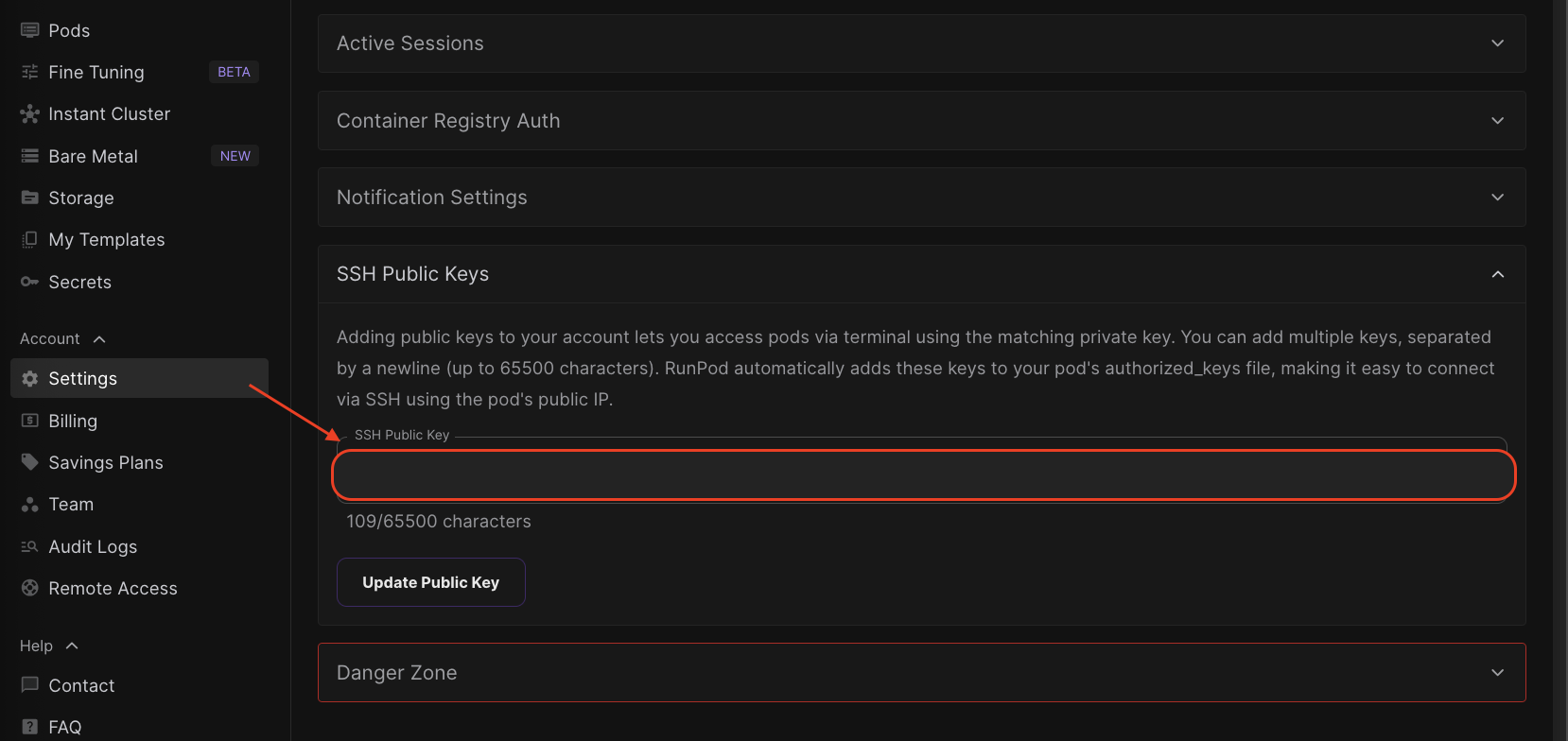
- Click Update Public Key
ssh into the server
ssh [server-ip] -i ~/
- Go to
Pods->Deploy-> create a pod -> wait till it creates -> clickConnect
yay! now you got powerful GPUs
- lets see what OS is it
root@f00742593164:/# uname -a
Linux f00742593164 6.8.0-49-generic #49~22.04.1-Ubuntu SMP PREEMPT_DYNAMIC Wed Nov 6 17:42:15 UTC 2 x86_64 x86_64 x86_64 GNU/Linux
-
alright, Ubuntu 22.04, classic
-
alright … same xxx, different day
-
install python, lets use uv this time
-
make it more intresting, lets build the vllm from source, so that
- in production, are u really sure you don’t want to customize it to fit your company’s need?
- are you sure vllm production-stack is mature enough?
-
I only have one machine, I could build few virtual pods, then add k8s to manage them, then use production-stack to get the “llm in production starter pack”
Install dependencies
Install uv python virtual environment manager
Install python
-
recommend python version:
python 3.12 -
give a little old
apt update && apt upgradefirst to fetch the latest packages- always do this first, makes sure your OS packages are clean and fresh
-
for Ubuntu you have these package managers:
apt(Debian-based)yum(Red Hat-based)dnf(Fedora-based)zypper(openSUSE-based)
apt update && apt upgrade
Lets check the GPU to make sure I’m not get scammed
root@f00742593164:/# nvidia-smi
Fri May 9 01:39:25 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.127.05 Driver Version: 550.127.05 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA H100 PCIe On | 00000000:61:00.0 Off | 0 |
| N/A 35C P0 48W / 310W | 1MiB / 81559MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Good…
Lets see if system has python or not
root@f00742593164:/# which python
# /usr/bin/python
root@f00742593164:/# whereis python
# python: /usr/bin/python
root@f00742593164:/# /usr/bin/python
# Python 3.10.12 (main, Feb 4 2025, 14:57:36) [GCC 11.4.0] on linux
# Type "help", "copyright", "credits" or "license" for more information.
# >>> exit()
Impressive, but we need 3.12 -_-
Well don’t worry, 🤓☝️ we can use uv, a python package and project manager, written in Rust🐐.
# Install uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# downloading uv 0.7.3 x86_64-unknown-linux-gnu
# no checksums to verify
# installing to /root/.local/bin
# uv
# uvx
# everything's installed!
#
# To add $HOME/.local/bin to your PATH, either restart your shell or run:
#
# source $HOME/.local/bin/env (sh, bash, zsh)
# source $HOME/.local/bin/env.fish (fish)
#
# know what shell you're using
echo $SHELL
# Add the env loader to your bash startup
#echo 'source $HOME/.local/bin/env' >> ~/.bashrc
# use this so that it won't accedentally crash the shell and disconnected
# but you have to do it everytime when login
export PATH="$HOME/.local/bin:$PATH"
root@f00742593164:/# echo $SHELL
/bin/bash
# Reload
source ~/.bashrc
# test uv
# root@f00742593164:/# uv
# An extremely fast Python package manager.
#
# Usage: uv [OPTIONS] <COMMAND>
#
# Commands:
# run Run a command or script
# init Create a new project
# add Add dependencies to the project
# remove Remove dependencies from the project
# sync Update the project's environment
# lock Update the project's lockfile
# export Export the project's lockfile to an alternate format
# tree Display the project's dependency tree
# tool Run and install commands provided by Python packages
# python Manage Python versions and installations
# pip Manage Python packages with a pip-compatible interface
# venv Create a virtual environment
# build Build Python packages into source distributions and wheels
# publish Upload distributions to an index
# cache Manage uv's cache
# self Manage the uv executable
# version Read or update the project's version
# help Display documentation for a command
#
# Cache options:
# -n, --no-cache Avoid reading from or writing to the cache, instead using a temporary directory for
# the duration of the operation [env: UV_NO_CACHE=]
# --cache-dir <CACHE_DIR> Path to the cache directory [env: UV_CACHE_DIR=]
#
# Python options:
# --managed-python Require use of uv-managed Python versions [env: UV_MANAGED_PYTHON=]
# --no-managed-python Disable use of uv-managed Python versions [env: UV_NO_MANAGED_PYTHON=]
# --no-python-downloads Disable automatic downloads of Python. [env: "UV_PYTHON_DOWNLOADS=never"]
#
# Global options:
# -q, --quiet...
# Use quiet output
# -v, --verbose...
# Use verbose output
# --color <COLOR_CHOICE>
# Control the use of color in output [possible values: auto, always, never]
# --native-tls
# Whether to load TLS certificates from the platform's native certificate store [env: UV_NATIVE_TLS=]
# --offline
# Disable network access [env: UV_OFFLINE=]
# --allow-insecure-host <ALLOW_INSECURE_HOST>
# Allow insecure connections to a host [env: UV_INSECURE_HOST=]
# --no-progress
# Hide all progress outputs [env: UV_NO_PROGRESS=]
# --directory <DIRECTORY>
# Change to the given directory prior to running the command
# --project <PROJECT>
# Run the command within the given project directory [env: UV_PROJECT=]
# --config-file <CONFIG_FILE>
# The path to a `uv.toml` file to use for configuration [env: UV_CONFIG_FILE=]
# --no-config
# Avoid discovering configuration files (`pyproject.toml`, `uv.toml`) [env: UV_NO_CONFIG=]
# -h, --help
# Display the concise help for this command
# -V, --version
# Display the uv version
#
# Use `uv help` for more details.
# create python virtual environment in one line
# NOTE: create this venv above both production-stack and vllm , for consistent
# uv [venv name] --python [python version]
uv venv --python 3.12 --seed
# --seed # Install seed packages (one or more of: `pip`, `setuptools`, and
# #`wheel`) into the virtual environment [env: UV_VENV_SEED=]
# root@f00742593164:/# uv venv --python 3.12 --seed
# Using CPython 3.12.10
# Creating virtual environment with seed packages at: .venv
# + pip==25.1.1
# Activate with: source .venv/bin/activate
source .venv/bin/activate
--seedoption will install essential packages into the virtual environment after it’s created, not python itself- So it’s like using apt-get install ppa-xxx, setup-tools … “pre-packages” like this before building python
Build vllm from source
- since it can build with cuda, lets check the cuda version
nvcc --version
# nvcc: NVIDIA (R) Cuda compiler driver
# Copyright (c) 2005-2022 NVIDIA Corporation
# Built on Wed_Sep_21_10:33:58_PDT_2022
# Cuda compilation tools, release 11.8, V11.8.89
# Build cuda_11.8.r11.8/compiler.31833905_0
-
build the vllm from source , with correct cuda version
-
clone my fork(you can just clone the original repo)
(.venv) root@f00742593164:/home# git clone https://github.com/davidgao7/vllm.git
Cloning into 'vllm'...
remote: Enumerating objects: 70376, done.
remote: Counting objects: 100% (189/189), done.
remote: Compressing objects: 100% (157/157), done.
remote: Total 70376 (delta 92), reused 32 (delta 32), pack-reused 70187 (from 3)
Receiving objects: 100% (70376/70376), 48.99 MiB | 15.81 MiB/s, done.
Resolving deltas: 100% (54878/54878), done.
-
build from source (for nividia cuda)
-
In the docs:
If you only need to change Python code, you can build and install vLLM without compilation. Using pip’s --editable flag, changes you make to the code will be reflected when you run vLLM, which is exactly what we want
cd vllm
VLLM_USE_PRECOMPILED=1 uv pip install --editable .
This command will do the following:
-
Look for the current branch in your vLLM clone(default branch: ).
-
Identify the corresponding base commit in the main branch.
-
Download the pre-built wheel of the base commit.
-
Use its compiled libraries in the installation.
(vllm) root@49924402e807:/workspace/vllm# VLLM_USE_PRECOMPILED=1 uv pip install --editable .
Resolved 146 packages in 24.08s
Built vllm @ file:///workspace/vllm
Prepared 1 package in 56.50s
░░░░░░░░░░░░░░░░░░░░ [0/146] Installing wheels... warning: Failed to hardlink files; falling back to full copy. This may lead to degraded performance.
If the cache and target directories are on different filesystems, hardlinking may not be supported.
If this is intentional, set `export UV_LINK_MODE=copy` or use `--link-mode=copy` to suppress this warning.
Installed 146 packages in 54.49s
+ aiohappyeyeballs==2.6.1
+ aiohttp==3.11.18
+ aiosignal==1.3.2
+ airportsdata==20250224
+ annotated-types==0.7.0
+ anyio==4.9.0
+ astor==0.8.1
+ attrs==25.3.0
+ blake3==1.0.4
+ cachetools==5.5.2
+ certifi==2025.4.26
+ charset-normalizer==3.4.2
+ click==8.1.8
+ cloudpickle==3.1.1
+ compressed-tensors==0.9.4
+ cupy-cuda12x==13.4.1
+ deprecated==1.2.18
+ depyf==0.18.0
+ dill==0.4.0
+ diskcache==5.6.3
+ distro==1.9.0
+ dnspython==2.7.0
+ einops==0.8.1
+ email-validator==2.2.0
+ fastapi==0.115.12
+ fastapi-cli==0.0.7
+ fastrlock==0.8.3
+ filelock==3.18.0
+ frozenlist==1.6.0
+ fsspec==2025.3.2
+ gguf==0.16.3
+ googleapis-common-protos==1.70.0
+ grpcio==1.71.0
+ h11==0.16.0
+ hf-xet==1.1.0
+ httpcore==1.0.9
+ httptools==0.6.4
+ httpx==0.28.1
+ huggingface-hub==0.31.1
+ idna==3.10
+ importlib-metadata==8.6.1
+ interegular==0.3.3
+ jinja2==3.1.6
+ jiter==0.9.0
+ jsonschema==4.23.0
+ jsonschema-specifications==2025.4.1
+ lark==1.2.2
+ llguidance==0.7.19
+ llvmlite==0.44.0
+ lm-format-enforcer==0.10.11
+ markdown-it-py==3.0.0
+ markupsafe==3.0.2
+ mdurl==0.1.2
+ mistral-common==1.5.4
+ mpmath==1.3.0
+ msgpack==1.1.0
+ msgspec==0.19.0
+ multidict==6.4.3
+ nest-asyncio==1.6.0
+ networkx==3.4.2
+ ninja==1.11.1.4
+ numba==0.61.2
+ numpy==2.2.5
+ nvidia-cublas-cu12==12.6.4.1
+ nvidia-cuda-cupti-cu12==12.6.80
+ nvidia-cuda-nvrtc-cu12==12.6.77
+ nvidia-cuda-runtime-cu12==12.6.77
+ nvidia-cudnn-cu12==9.5.1.17
+ nvidia-cufft-cu12==11.3.0.4
+ nvidia-cufile-cu12==1.11.1.6
+ nvidia-curand-cu12==10.3.7.77
+ nvidia-cusolver-cu12==11.7.1.2
+ nvidia-cusparse-cu12==12.5.4.2
+ nvidia-cusparselt-cu12==0.6.3
+ nvidia-nccl-cu12==2.26.2
+ nvidia-nvjitlink-cu12==12.6.85
+ nvidia-nvtx-cu12==12.6.77
+ openai==1.78.0
+ opencv-python-headless==4.11.0.86
+ opentelemetry-api==1.32.1
+ opentelemetry-exporter-otlp==1.32.1
+ opentelemetry-exporter-otlp-proto-common==1.32.1
+ opentelemetry-exporter-otlp-proto-grpc==1.32.1
+ opentelemetry-exporter-otlp-proto-http==1.32.1
+ opentelemetry-proto==1.32.1
+ opentelemetry-sdk==1.32.1
+ opentelemetry-semantic-conventions==0.53b1
+ opentelemetry-semantic-conventions-ai==0.4.7
+ outlines==0.1.11
+ outlines-core==0.1.26
+ packaging==25.0
+ partial-json-parser==0.2.1.1.post5
+ pillow==11.2.1
+ prometheus-client==0.21.1
+ prometheus-fastapi-instrumentator==7.1.0
+ propcache==0.3.1
+ protobuf==5.29.4
+ psutil==7.0.0
+ py-cpuinfo==9.0.0
+ pycountry==24.6.1
+ pydantic==2.11.4
+ pydantic-core==2.33.2
+ pygments==2.19.1
+ python-dotenv==1.1.0
+ python-json-logger==3.3.0
+ python-multipart==0.0.20
+ pyyaml==6.0.2
+ pyzmq==26.4.0
+ ray==2.46.0
+ referencing==0.36.2
+ regex==2024.11.6
+ requests==2.32.3
+ rich==14.0.0
+ rich-toolkit==0.14.5
+ rpds-py==0.24.0
+ safetensors==0.5.3
+ scipy==1.15.3
+ sentencepiece==0.2.0
+ setuptools==79.0.1
+ shellingham==1.5.4
+ six==1.17.0
+ sniffio==1.3.1
+ starlette==0.46.2
+ sympy==1.14.0
+ tiktoken==0.9.0
+ tokenizers==0.21.1
+ torch==2.7.0
+ torchaudio==2.7.0
+ torchvision==0.22.0
+ tqdm==4.67.1
+ transformers==4.51.3
+ triton==3.3.0
+ typer==0.15.3
+ typing-extensions==4.13.2
+ typing-inspection==0.4.0
+ urllib3==2.4.0
+ uvicorn==0.34.2
+ uvloop==0.21.0
+ vllm==0.1.dev6367+g3d1e387.precompiled (from file:///workspace/vllm)
+ watchfiles==1.0.5
+ websockets==15.0.1
+ wrapt==1.17.2
+ xformers==0.0.30
+ xgrammar==0.1.18
+ yarl==1.20.0
+ zipp==3.21.0
[!NOTE] 🤡 20GB is not engough to install the package
Usually workspace/ has more storage.
(.venv) root@f00742593164:/home/vllm# df -h
Filesystem Size Used Avail Use% Mounted on
overlay 20G 12G 8.5G 58% /
tmpfs 64M 0 64M 0% /dev
tmpfs 756G 0 756G 0% /sys/fs/cgroup
shm 88G 0 88G 0% /dev/shm
/dev/sda2 3.5T 22G 3.3T 1% /usr/bin/nvidia-smi
/dev/sdb 20G 0 20G 0% /workspace
tmpfs 756G 12K 756G 1% /proc/driver/nvidia
tmpfs 756G 4.0K 756G 1% /etc/nvidia/nvidia-application-profiles-rc.d
tmpfs 152G 52M 152G 1% /run/nvidia-persistenced/socket
tmpfs 756G 0 756G 0% /proc/acpi
tmpfs 756G 0 756G 0% /proc/scsi
tmpfs 756G 0 756G 0% /sys/firmware
tmpfs 756G 0 756G 0% /sys/devices/virtual/powercap
(.venv) root@f00742593164:/home/vllm# df -h --output=source,target,size,used,avail
Filesystem Mounted on Size Used Avail
overlay / 20G 12G 8.5G
tmpfs /dev 64M 0 64M
tmpfs /sys/fs/cgroup 756G 0 756G
shm /dev/shm 88G 0 88G
/dev/sda2 /usr/bin/nvidia-smi 3.5T 22G 3.3T
/dev/sdb /workspace 20G 0 20G
tmpfs /proc/driver/nvidia 756G 12K 756G
tmpfs /etc/nvidia/nvidia-application-profiles-rc.d 756G 4.0K 756G
tmpfs /run/nvidia-persistenced/socket 152G 52M 152G
tmpfs /proc/acpi 756G 0 756G
tmpfs /proc/scsi 756G 0 756G
tmpfs /sys/firmware 756G 0 756G
tmpfs /sys/devices/virtual/powercap 756G 0 756G
(.venv) root@f00742593164:/home/vllm# cd ..
(.venv) root@f00742593164:/home# mv vllm/ ../workspace/
(.venv) root@f00742593164:/home# ls
(.venv) root@f00742593164:/home# cd ..
(.venv) root@f00742593164:/# cd workspace/
(.venv) root@f00742593164:/workspace# ls
vllm
(.venv) root@f00742593164:/workspace# cd vllm
(.venv) root@f00742593164:/workspace/vllm# df -h --output=source,target,size,used,avail
Filesystem Mounted on Size Used Avail
overlay / 20G 11G 9.6G
tmpfs /dev 64M 0 64M
tmpfs /sys/fs/cgroup 756G 0 756G
shm /dev/shm 88G 0 88G
/dev/sda2 /usr/bin/nvidia-smi 3.5T 22G 3.3T
/dev/sdb /workspace 20G 1.2G 19G
tmpfs /proc/driver/nvidia 756G 12K 756G
tmpfs /etc/nvidia/nvidia-application-profiles-rc.d 756G 4.0K 756G
tmpfs /run/nvidia-persistenced/socket 152G 52M 152G
tmpfs /proc/acpi 756G 0 756G
tmpfs /proc/scsi 756G 0 756G
tmpfs /sys/firmware 756G 0 756G
tmpfs /sys/devices/virtual/powercap 756G 0 756G
(.venv) root@f00742593164:/workspace/vllm# rm -rf ../../.venv/
Git structure should’ve not changed, double check…
(.venv) root@f00742593164:/workspace/vllm# git remote -v
origin https://github.com/davidgao7/vllm.git (fetch)
origin https://github.com/davidgao7/vllm.git (push)
Noice, 😅
Try that again… Oh yea don’t forget to create virtual environment again and activate it.
VLLM_USE_PRECOMPILED=1 pip install --editable .
Install python env
(.venv) root@f00742593164:/workspace/vllm# uv venv --python 3.12 --seed
Using CPython 3.12.10
Creating virtual environment with seed packages at: .venv
warning: Failed to hardlink files; falling back to full copy. This may lead to degraded performance.
If the cache and target directories are on different filesystems, hardlinking may not be supported.
If this is intentional, set `export UV_LINK_MODE=copy` or use `--link-mode=copy` to suppress this warning.
+ pip==25.1.1
Activate with: source .venv/bin/activate
(.venv) root@f00742593164:/workspace/vllm# source .venv/bin/activate
(vllm) root@f00742593164:/workspace/vllm# python
Python 3.12.10 (main, Apr 9 2025, 04:03:51) [Clang 20.1.0 ] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
(vllm) root@f00742593164:/workspace/vllm#
Install dependencies
VLLM_USE_PRECOMPILED=1 pip install --editable .
Let’s try if vllm really work, here is an example script
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main():
# Create an LLM.
llm = LLM(model="facebook/opt-125m")
# Generate texts from the prompts.
# The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
print("\nGenerated Outputs:\n" + "-" * 60)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}")
print(f"Output: {generated_text!r}")
print("-" * 60)
if __name__ == "__main__":
main()
In this example, we pull the opt-125m model from huggingface, and generate some text with it.
uv run examples/offline_inference/basic/basic.py
Finally, if your machine is powerful enough(and you store at correct large disk), you could run one inference(multi-inferences when speaking about per token)
(vllm) root@49924402e807:/workspace/vllm# uv run examples/offline_inference/basic/basic.py
INFO 05-09 06:46:59 [__init__.py:248] Automatically detected platform cuda.
config.json: 100%|███████████████████████████████████████████████████████████████| 651/651 [00:00<00:00, 3.33MB/s]
INFO 05-09 06:47:58 [config.py:752] This model supports multiple tasks: {'classify', 'score', 'generate', 'embed', 'reward'}. Defaulting to 'generate'.
INFO 05-09 06:47:58 [config.py:2057] Chunked prefill is enabled with max_num_batched_tokens=8192.
tokenizer_config.json: 100%|█████████████████████████████████████████████████████| 685/685 [00:00<00:00, 4.21MB/s]
vocab.json: 100%|██████████████████████████████████████████████████████████████| 899k/899k [00:00<00:00, 3.76MB/s]
merges.txt: 100%|██████████████████████████████████████████████████████████████| 456k/456k [00:00<00:00, 2.91MB/s]
special_tokens_map.json: 100%|███████████████████████████████████████████████████| 441/441 [00:00<00:00, 3.28MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████| 137/137 [00:00<00:00, 809kB/s]
INFO 05-09 06:48:05 [core.py:61] Initializing a V1 LLM engine (v0.1.dev6367+g3d1e387) with config: model='facebook/opt-125m', speculative_config=None, tokenizer='facebook/opt-125m', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=2048, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend=''), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=None, served_model_name=facebook/opt-125m, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, pooler_config=None, compilation_config={"level":3,"custom_ops":["none"],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output"],"use_inductor":true,"compile_sizes":[],"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[512,504,496,488,480,472,464,456,448,440,432,424,416,408,400,392,384,376,368,360,352,344,336,328,320,312,304,296,288,280,272,264,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"max_capture_size":512}
WARNING 05-09 06:48:09 [utils.py:2587] Methods determine_num_available_blocks,device_config,get_cache_block_size_bytes,initialize_cache not implemented in <vllm.v1.worker.gpu_worker.Worker object at 0x7fb0ff70d8b0>
INFO 05-09 06:48:10 [parallel_state.py:1004] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0
INFO 05-09 06:48:10 [cuda.py:221] Using Flash Attention backend on V1 engine.
WARNING 05-09 06:48:10 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
INFO 05-09 06:48:10 [gpu_model_runner.py:1393] Starting to load model facebook/opt-125m...
INFO 05-09 06:48:11 [weight_utils.py:257] Using model weights format ['*.bin']
pytorch_model.bin: 100%|███████████████████████████████████████████████████████| 251M/251M [00:03<00:00, 83.0MB/s]
INFO 05-09 06:48:15 [weight_utils.py:273] Time spent downloading weights for facebook/opt-125m: 3.667131 seconds
Loading pt checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading pt checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 3.20it/s]
Loading pt checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 3.19it/s]
INFO 05-09 06:48:15 [default_loader.py:278] Loading weights took 0.32 seconds
INFO 05-09 06:48:15 [gpu_model_runner.py:1411] Model loading took 0.2389 GiB and 4.768521 seconds
INFO 05-09 06:48:24 [backends.py:437] Using cache directory: /root/.cache/vllm/torch_compile_cache/f75f64201d/rank_0_0 for vLLM's torch.compile
INFO 05-09 06:48:24 [backends.py:447] Dynamo bytecode transform time: 8.85 s
INFO 05-09 06:48:27 [backends.py:138] Cache the graph of shape None for later use
INFO 05-09 06:48:34 [backends.py:150] Compiling a graph for general shape takes 9.91 s
INFO 05-09 06:48:37 [monitor.py:33] torch.compile takes 18.75 s in total
INFO 05-09 06:48:38 [kv_cache_utils.py:639] GPU KV cache size: 582,208 tokens
INFO 05-09 06:48:38 [kv_cache_utils.py:642] Maximum concurrency for 2,048 tokens per request: 284.28x
INFO 05-09 06:48:59 [gpu_model_runner.py:1774] Graph capturing finished in 21 secs, took 0.20 GiB
INFO 05-09 06:48:59 [core.py:163] init engine (profile, create kv cache, warmup model) took 43.73 seconds
INFO 05-09 06:48:59 [core_client.py:442] Core engine process 0 ready.
Adding requests: 100%|█████████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 233.82it/s]
Processed prompts: 100%|█████| 4/4 [00:00<00:00, 11.66it/s, est. speed input: 75.80 toks/s, output: 186.57 toks/s]
Generated Outputs:
------------------------------------------------------------
Prompt: 'Hello, my name is'
Output: ' Ken Li and I’m a computer science student. My primary interest is'
------------------------------------------------------------
Prompt: 'The president of the United States is'
Output: ' attempting to subvert a very important issue, one which many of us are of'
------------------------------------------------------------
Prompt: 'The capital of France is'
Output: ' filled with tourists, retirees and independent artists but, by far, the most popular'
------------------------------------------------------------
Prompt: 'The future of AI is'
Output: ' becoming more connected. This requires more research and development than ever before. With the'
------------------------------------------------------------
Love the verbose logs.
Message from future me: you’ll face a lot of unrelated problem when trying to deploy on a single pod. so start with cluster if you have!
Now for the real problem needs to solve, we need to add the /v1/audio/transcriptions support to the production stack.
POC: Add /v1/audio/transcriptions Support to vLLM Production-Stack
1. Background
- GitHub Issue: vllm-project/production-stack#410
- Problem:
The vLLM backend already supports/v1/audio/transcriptions(Whisper-based ASR),
but the production-stack router does not expose it, causing 404 errors. - Goal:
Extend the production-stack router to expose the/v1/audio/transcriptionsendpoint and successfully forward requests to the backend.
2. Environment Setup
-
spin up an instant cluster in runpod is MUCH easier
-
Through sweats and tears, trails and errors, I finally find the correct way: use the Instant clusters
| Pain in single pod | Why it breaks | How Instant Clusters fix it |
|---|---|---|
| OverlayFS / bind‑mount denied | Container security on a pod | Nodes are full VMs → kernel features allowed (RunPod Docs) |
/dev/kmsg & other device files missing |
Device files masked | Full device namespace, kubelet starts cleanly |
| Static intra‑cluster networking needed | Pod IPs are ephemeral | Each node gets a static NODE_ADDR; primary node gets PRIMARY_ADDR (RunPod Docs) |
| GPU scheduling | No privileged runtime | Install NVIDIA device‑plugin once; GPUs appear in kubectl describe node |
| Scalability | Single host only | Up to 8 nodes × 8 GPUs per node (64 GPU max) with high‑speed mesh (RunPod Docs) |
So what machine configuration should I choose?
| Option | Meets K8s‑production need? | Gives GPU node? | Avoids earlier sandbox errors? | Practical notes |
|---|---|---|---|---|
| RunPod Single Pod | ✘ (kubelet fails) | ✔ RTX 3090 | ✘ sandbox limits | Already ruled out |
| RunPod Instant Cluster | ✘ (K8s not supported) | ✔ multi‑GPU | ✔ root VM, but no kube‑API | Great for PyTorch/Slurm, not Helm |
| RunPod Bare Metal | ✔ install K3s easily | ✔ pick 1–8 GPUs | ✔ full server | Same RunPod UI; hourly billing |
| AWS / Azure / GCP managed K8s (EKS / AKS / GKE) | ✔ fully managed control‑plane | ✔ add GPU node‑pool | ✔ real VMs | Slightly higher cost; IAM setup |
| Self‑host K3s on any GPU VM (Lambda, Paperspace, Hetzner, OCI) | ✔ single‑node or multi‑node | ✔ if you rent GPU VM | ✔ full root | You manage everything, but simple for dev work |
- uhh, I still have 10 bucks remain on runpod…
- Bare metal cluster cheapest one cost hundreds of bucks :(
- I do need a k8s environment
I found GKE is the cheapest option
Why GKE?
- Focus on your app, not infrastructure: GKE handles the heavy lifting of managing Kubernetes, letting you concentrate on building and innovating.
- GPU Power Made Easy: GKE makes it straightforward to use GPUs, which is crucial for your AI/ML workloads and resolving your specific bug.
- Scale Effortlessly: GKE grows with you, easily handling increased demands on your application without you having to worry about the details.
- Production-Ready Reproduction: GKE gives you the environment you need to pinpoint and fix the router pod, vLLM + Whisper worker, and GPU interaction bug.
- Plays Well with Everything: GKE integrates smoothly with other Google Cloud services you might need. Cost-Effective: GKE has features like Autopilot mode and cost optimization tools to help you manage your spending.
- Secure: GKE offers built-in security features to protect your applications. Future-Proof: Kubernetes is the industry standard, and GKE is a leading managed Kubernetes service.
- standard cluster
- us-east-1
- fleet registration: A Google Cloud fleet is a top‑level “super‑cluster” object that lets you manage multiple Kubernetes clusters (GKE, on‑prem, or other clouds) as a single unit—enabling shared policies, multi‑cluster services, and centralized observability with no extra cost.
- CIDR only allow my ip addr
Connect to cluster
For google cloud we can install gcloud cli tool, and use gcloud container clusters get-credentials to connect to the cluster
gcloud container clusters get-credentials autopilot-cluster-1 --region us-east1
- If you don’t have
gcloud, here is a tutorial how to install it:
wget https://dl.google.com/dl/cloudsdk/channels/rapid/downloads/google-cloud-cli-darwin-arm.tar.gz
tar -xf google-cloud-cli-darwin-arm.tar.gz
cd google-cloud-sdk
chmod +x install.sh # just in case...
sh install.sh
And it’s writing on your rc file… Check the execution order, you can modify yourself.
Then login your gcloud cli, and setup corresponding project id
- login
gcloud auth login
- setup corresponding project id
gcloud config set project gen-lang-client-0475913374
- connect the local machine
kubectlto cluster
gcloud container clusters get-credentials autopilot-cluster-1 --region us-east1
# Fetching cluster endpoint and auth data.
# CRITICAL: ACTION REQUIRED: gke-gcloud-auth-plugin, which is needed for continued use of kubectl, was not found or is not executable. Install gke-gcloud-auth-plugin for use with kubectl by following https://cloud.google.com/kubernetes-engine/docs/how-to/cluster-access-for-kubectl#install_plugin
# kubeconfig entry generated for autopilot-cluster-1.
Ok more installations,
- Install required plugins
gcloud components install gke-gcloud-auth-plugin
#
# Your current Google Cloud CLI version is: 521.0.0
# Installing components from version: 521.0.0
#
# ┌────────────────────────────────────────────────────────────────┐
# │ These components will be installed. │
# ├────────────────────────────────────────────┬─────────┬─────────┤
# │ Name │ Version │ Size │
# ├────────────────────────────────────────────┼─────────┼─────────┤
# │ gke-gcloud-auth-plugin (Platform Specific) │ 0.5.10 │ 3.3 MiB │
# └────────────────────────────────────────────┴─────────┴─────────┘
#
# For the latest full release notes, please visit:
# https://cloud.google.com/sdk/release_notes
#
# Once started, canceling this operation may leave your SDK installation in an inconsistent state.
#
# Do you want to continue (Y/n)? Y
#
# Performing in place update...
#
# ╔════════════════════════════════════════════════════════════╗
# ╠═ Downloading: gke-gcloud-auth-plugin ═╣
# ╠════════════════════════════════════════════════════════════╣
# ╠═ Downloading: gke-gcloud-auth-plugin (Platform Specific) ═╣
# ╠════════════════════════════════════════════════════════════╣
# ╠═ Installing: gke-gcloud-auth-plugin ═╣
# ╠════════════════════════════════════════════════════════════╣
# ╠═ Installing: gke-gcloud-auth-plugin (Platform Specific) ═╣
# ╚════════════════════════════════════════════════════════════╝
#
# Performing post processing steps...done.
#
# Update done!
- Try to initialize the cluster again
gcloud container clusters get-credentials autopilot-cluster-1 --region us-east1 # or other region
# Fetching cluster endpoint and auth data.
# kubeconfig entry generated for autopilot-cluster-1.
[!NOTE] Performance Monitoring: To monitor and verify the latency and performance between your location and the GKE cluster, you can utilize tools like GCPing, which provides latency measurements to various Google Cloud regions.
- Connect to the cluster 🔥
> kubectl get nodes
No resources found
Nice, it’s working
Install NVIDIA GPU Device Plugin (Need?)
- Currently no, GKE Autopilot automatically provisions GPU nodes and installs the necessary NVIDIA drivers and device plugins when you deploy a workload that requests GPU resources.
Psst Here is the Plugin repo
- Github: NVIDIA/k8s-device-plugin
- NGC Catalog: NIVIDIA Device Plugin
Reproducing the issue
Deploy the current production-stack on GCP
For GCP, there are 2 tutorials:
/tutorials/cloud_deployments/02-GCP-GKE-deployment.md/deployment_on_cloud/gcp/README.md/deployment_on_cloud/gcp/OPT125_CPU/README.md
I already have GKE cluster, I just need to manually depoly the vLLM production stack using helm, no need to use the scripts to create cluster.
Add official Helm repo to my cluster.
helm repo add production-stack https://vllm-project.github.io/production-stack-helm-charts/
helm repo update
[!NOTE] I can access autopilot k8s cluster locally, think of autopilot as a serverless kubernetes experience. If I was to gain SSH access to an Autopilot node, it would be considered a security vulnerability because I could potentially bypass the Kubernetes API and run commands directly on the node.
Here is the official docs for vllm production deployment For code, we will use the Helm repo
- The official documentation is using lmcache repo, which might be outdated.
So , the correct way to deploy production-stack is
# adds the URL to local list of helm repositories
helm repo add vllm https://vllm-project.github.io/production-stack
# > helm repo add vllm https://vllm-project.github.io/production-stack
# zsh: command not found: helm
# downloads and refreshes the latest list of charts from the repo added
helm repo update
Instead of lmcache.github.io/helm/
😅need to install helm, yay one more install
To manage Kubernetes deployments on GKE Autopilot cluster using Helm, need to install Helm CLI on local machine.
Here is the official docs on how to install Helm Here is the one-liner
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
#
# > curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
# % Total % Received % Xferd Average Speed Time Time Time Current
# Dload Upload Total Spent Left Speed
# 100 11913 100 11913 0 0 61922 0 --:--:-- --:--:-- --:--:-- 62046
# Downloading https://get.helm.sh/helm-v3.17.3-darwin-arm64.tar.gz
# Verifying checksum... Done.
# Preparing to install helm into /usr/local/bin
# Password:
# helm installed into /usr/local/bin/helm
Rerun the repo add and update command
# adds the URL to local list of helm repositories
helm repo add vllm https://vllm-project.github.io/production-stack
# "vllm" has been added to your repositories
# downloads and refreshes the latest list of charts from the repo added
helm repo update
# Hang tight while we grab the latest from your chart repositories...
# ...Successfully got an update from the "vllm" chart repository
# Update Complete. ⎈Happy Helming!⎈
helm search repo vllm
# NAME CHART VERSION APP VERSION DESCRIPTION
# vllm/vllm-stack 0.1.2 The stack deployment of vLLM
# quick sanity check
helm show values vllm/vllm-stack
# # -- Default values for llmstack helm chart
# # -- Declare variables to be passed into your templates.
#
# # -- Serving engine configuratoon
# servingEngineSpec:
# enableEngine: true
# # -- Customized labels for the serving engine deployment
# labels:
# environment: "test"
# release: "test"
# # vllmApiKey: (optional) api key for securing the vLLM models. Can be either:
# # - A string containing the token directly (will be stored in a generated secret)
# # - An object referencing an existing secret:
# # secretName: "my-existing-secret"
# # secretKey: "vllm-api-key"
# #
# # modelSpec - configuring multiple serving engines deployments that runs different models
# # Each entry in the modelSpec array should contain the following fields:
# # - name: (string) The name of the model, e.g., "example-model"
# # - repository: (string) The repository of the model, e.g., "vllm/vllm-openai"
# # - tag: (string) The tag of the model, e.g., "latest"
# # - imagePullSecret: (Optional, string) Name of secret with credentials to private container repository, e.g. "secret"
# # - modelURL: (string) The URL of the model, e.g., "facebook/opt-125m"
# # - chatTemplate: (Optional, string) Chat template (Jinga2) specifying tokenizer configuration, e.g. "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ 'Question:\n' + message['content'] + '\n\n' }}{% elif message['role'] == 'system' %}\n{{ 'System:\n' + message['content'] + '\n\n' }}{% elif message['role'] == 'assistant' %}{{ 'Answer:\n' + message['content'] + '\n\n' }}{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ 'Answer:\n' }}{% endif %}{% endfor %}"
# #
# # - replicaCount: (int) The number of replicas for the model, e.g. 1
# # - requestCPU: (int) The number of CPUs requested for the model, e.g. 6
# # - requestMemory: (string) The amount of memory requested for the model, e.g., "16Gi"
# # - requestGPU: (int) The number of GPUs requested for the model, e.g., 1
# # - requestGPUType: (Optional, string) The type of GPU requested, e.g., "nvidia.com/mig-4g.71gb". If not specified, defaults to "nvidia.com/gpu"
# # - limitCPU: (Optional, string) The CPU limit for the model, e.g., "8"
# # - limitMemory: (Optional, string) The memory limit for the model, e.g., "32Gi"
# # Note: If limitCPU and limitMemory are not specified, only GPU resources will have limits set equal to their requests.
# # - pvcStorage: (Optional, string) The amount of storage requested for the model, e.g., "50Gi".
# # - pvcAccessMode: (Optional, list) The access mode policy for the mounted volume, e.g., ["ReadWriteOnce"]
# # - storageClass: (Optional, String) The storage class of the PVC e.g., "", default is ""
# # - pvcMatchLabels: (Optional, map) The labels to match the PVC, e.g., {model: "opt125m"}
# # - extraVolumes: (Optional, list) Additional volumes to add to the pod, in Kubernetes volume format. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#volume-v1-core
# # Example for an emptyDir volume:
# # extraVolumes:
# # - name: tmp-volume
# # emptyDir:
# # medium: ""
# # sizeLimit: 5Gi
# # - extraVolumeMounts: (Optional, list) Additional volume mounts to add to the container, in Kubernetes volumeMount format. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#volumemount-v1-core
# # Example for mounting the tmp-volume to /tmp:
# # extraVolumeMounts:
# # - name: tmp-volume
# # mountPath: /tmp
# # - initContainer: (optional, list of objects) The configuration for the init container to be run before the main container.
# # - name: (string) The name of the init container, e.g., "init"
# # - image: (string) The Docker image for the init container, e.g., "busybox:latest"
# # - command: (optional, list) The command to run in the init container, e.g., ["sh", "-c"]
# # - args: (optional, list) Additional arguments to pass to the command, e.g., ["ls"]
# # - env: (optional, list) List of environment variables to set in the container, each being a map with:
# # - resources: (optional, map) The resource requests and limits for the container:
# # - mountPvcStorage: (optional, bool) Whether to mount the model's volume.
# #
# # - vllmConfig: (optional, map) The configuration for the VLLM model, supported options are:
# # - enablePrefixCaching: (optional, bool) Enable prefix caching, e.g., false
# # - enableChunkedPrefill: (optional, bool) Enable chunked prefill, e.g., false
# # - maxModelLen: (optional, int) The maximum model length, e.g., 16384
# # - dtype: (optional, string) The data type, e.g., "bfloat16"
# # - tensorParallelSize: (optional, int) The degree of tensor parallelism, e.g., 2
# # - maxNumSeqs: (optional, int) Maximum number of sequences to be processed in a single iteration., e.g., 32
# # - maxLoras: (optional, int) The maximum number of LoRA models to be loaded in a single batch, e.g., 4
# # - gpuMemoryUtilization: (optional, float) The fraction of GPU memory to be used for the model executor, which can range from 0 to 1. e.g., 0.95
# # - extraArgs: (optional, list) Extra command line arguments to pass to vLLM, e.g., ["--disable-log-requests"]
# #
# # - lmcacheConfig: (optional, map) The configuration of the LMCache for KV offloading, supported options are:
# # - enabled: (optional, bool) Enable LMCache, e.g., true
# # - cpuOffloadingBufferSize: (optional, string) The CPU offloading buffer size, e.g., "30"
# #
# # - hf_token: (optional) Hugging Face token configuration. Can be either:
# # - A string containing the token directly (will be stored in a generated secret)
# # - An object referencing an existing secret:
# # secretName: "my-existing-secret"
# # secretKey: "hf-token-key"
# #
# # - env: (optional, list) The environment variables to set in the container, e.g., your HF_TOKEN
# #
# # - nodeSelectorTerms: (optional, list) The node selector terms to match the nodes
# #
# # - shmSize: (optional, string) The size of the shared memory, e.g., "20Gi"
# #
# # Example:
# # vllmApiKey: "vllm_xxxxxxxxxxxxx"
# # modelSpec:
# # - name: "mistral"
# # repository: "lmcache/vllm-openai"
# # tag: "latest"
# # modelURL: "mistralai/Mistral-7B-Instruct-v0.2"
# # replicaCount: 1
# #
# # requestCPU: 10
# # requestMemory: "64Gi"
# # requestGPU: 1
# #
# # pvcStorage: "50Gi"
# # pvcAccessMode:
# # - ReadWriteOnce
# # pvcMatchLabels:
# # model: "mistral"
# # initContainer:
# # name: my-container
# # image: busybox
# # command: ["sh"]
# # env: {}
# # args: []
# # resources: {}
# # mountPvcStorage: true
# #
# # vllmConfig:
# # enableChunkedPrefill: false
# # enablePrefixCaching: false
# # maxModelLen: 16384
# # dtype: "bfloat16"
# # maxNumSeqs: 32
# # gpuMemoryUtilization: 0.95
# # maxLoras: 4
# # extraArgs: ["--disable-log-requests", "--trust-remote-code"]
# #
# # lmcacheConfig:
# # enabled: true
# # cpuOffloadingBufferSize: "30"
# #
# # hf_token: "hf_xxxxxxxxxxxxx"
# #
# #
# # nodeSelectorTerms:
# # - matchExpressions:
# # - key: nvidia.com/gpu.product
# # operator: "In"
# # values:
# # - "NVIDIA-RTX-A6000"
# modelSpec: []
#
# # -- Container port
# containerPort: 8000
# # -- Service port
# servicePort: 80
#
# # -- Set other environment variables from config map
# configs: {}
#
# # -- deployment strategy
# strategy: {}
#
# # -- Readiness probe configuration
# startupProbe:
# # -- Number of seconds after the container has started before startup probe is initiated
# initialDelaySeconds: 15
# # -- How often (in seconds) to perform the startup probe
# periodSeconds: 10
# # -- Number of times after which if a probe fails in a row, Kubernetes considers that the overall check has failed: the container is not ready
# failureThreshold:
# 60
# # -- Configuration of the Kubelet http request on the server
# httpGet:
# # -- Path to access on the HTTP server
# path: /health
# # -- Name or number of the port to access on the container, on which the server is listening
# port: 8000
#
# # -- Liveness probe configuration
# livenessProbe:
# # -- Number of seconds after the container has started before liveness probe is initiated
# initialDelaySeconds: 15
# # -- Number of times after which if a probe fails in a row, Kubernetes considers that the overall check has failed: the container is not alive
# failureThreshold: 3
# # -- How often (in seconds) to perform the liveness probe
# periodSeconds: 10
# # -- Configuration of the Kubelet http request on the server
# httpGet:
# # -- Path to access on the HTTP server
# path: /health
# # -- Name or number of the port to access on the container, on which the server is listening
# port: 8000
#
# # -- Disruption Budget Configuration
# maxUnavailablePodDisruptionBudget: ""
#
# # -- Tolerations configuration (when there are taints on nodes)
# # Example:
# # tolerations:
# # - key: "node-role.kubernetes.io/control-plane"
# # operator: "Exists"
# # effect: "NoSchedule"
# tolerations: []
#
# # -- RuntimeClassName configuration, set to "nvidia" if the model requires GPU
# runtimeClassName: "nvidia"
#
# # -- SchedulerName configuration
# schedulerName: ""
#
# # -- Pod-level security context configuration. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#podsecuritycontext-v1-core
# securityContext: {}
# # -- Run as a non-root user ID
# # runAsUser: 1000
# # -- Run with a non-root group ID
# # runAsGroup: 1000
# # -- Run as non-root
# # runAsNonRoot: true
# # -- Set the seccomp profile
# # seccompProfile:
# # type: RuntimeDefault
# # -- Drop all capabilities
# # capabilities:
# # drop:
# # - ALL
# # -- Set the file system group ID for all containers
# # fsGroup: 1000
#
# # -- Container-level security context configuration. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#securitycontext-v1-core
# containerSecurityContext:
# # -- Run as non-root
# runAsNonRoot: false
# # -- Don't allow privilege escalation
# # allowPrivilegeEscalation: false
# # -- Drop all capabilities
# # capabilities:
# # drop:
# # - ALL
# # -- Read-only root filesystem
# # readOnlyRootFilesystem: true
#
# routerSpec:
# # -- The docker image of the router. The following values are defaults:
# repository: "lmcache/lmstack-router"
# tag: "latest"
# imagePullPolicy: "Always"
#
# # -- Whether to enable the router service
# enableRouter: true
#
# # -- Number of replicas
# replicaCount: 1
#
# # -- Container port
# containerPort: 8000
#
# # -- Service type
# serviceType: ClusterIP
#
# # -- Service port
# servicePort: 80
#
# # -- Service discovery mode, supports "k8s" or "static". Defaults to "k8s" if not set.
# serviceDiscovery: "k8s"
#
# # -- If serviceDiscovery is set to "static", the comma-separated values below are required. There needs to be the same number of backends and models
# staticBackends: ""
# staticModels: ""
#
# # -- routing logic, could be "roundrobin" or "session"
# routingLogic: "roundrobin"
#
# # -- session key if using "session" routing logic
# sessionKey: ""
#
# # -- extra router commandline arguments
# extraArgs: []
#
# # -- Interval in seconds to scrape the serving engine metrics
# engineScrapeInterval: 15
#
# # -- Window size in seconds to calculate the request statistics
# requestStatsWindow: 60
#
# # -- deployment strategy
# strategy: {}
#
# # vllmApiKey: (optional) api key for securing the vLLM models. Must be an object referencing an existing secret
# # secretName: "my-existing-secret"
# # secretKey: "vllm-api-key"
#
# # -- router resource requests and limits
# resources:
# requests:
# cpu: "4"
# memory: "16G"
# limits:
# cpu: "8"
# memory: "32G"
#
# # -- Customized labels for the router deployment
# labels:
# environment: "router"
# release: "router"
#
# ingress:
# # -- Enable ingress controller resource
# enabled: false
#
# # -- IngressClass that will be used to implement the Ingress
# className: ""
#
# # -- Additional annotations for the Ingress resource
# annotations:
# {}
# # kubernetes.io/ingress.class: alb
# # kubernetes.io/ingress.class: nginx
# # kubernetes.io/tls-acme: "true"
#
# # The list of hostnames to be covered with this ingress record.
# hosts:
# - host: vllm-router.local
# paths:
# - path: /
# pathType: Prefix
#
# # -- The tls configuration for hostnames to be covered with this ingress record.
# tls: []
# # - secretName: vllm-router-tls
# # hosts:
# # - vllm-router.local
#
# # The node selector terms to match the nodes
# # Example:
# # nodeSelectorTerms:
# # - matchExpressions:
# # - key: nvidia.com/gpu.product
# # operator: "In"
# # values:
# # - "NVIDIA-RTX-A6000"
# nodeSelectorTerms: []
#
# # -- TODO: Readiness probe configuration
# #startupProbe:
# # # -- Number of seconds after the container has started before startup probe is initiated
# # initialDelaySeconds: 5
# # # -- How often (in seconds) to perform the startup probe
# # periodSeconds: 5
# # # -- Number of times after which if a probe fails in a row, Kubernetes considers that the overall check has failed: the container is not ready
# # failureThreshold: 100
# # # -- Configuration of the Kubelet http request on the server
# # httpGet:
# # # -- Path to access on the HTTP server
# #
Let’s parse the yaml file
> helm show values vllm/vllm-stack | yq
# -- Default values for llmstack helm chart
# -- Declare variables to be passed into your templates.
# -- Serving engine configuratoon
servingEngineSpec:
enableEngine: true
# -- Customized labels for the serving engine deployment
labels:
environment: "test"
release: "test"
# vllmApiKey: (optional) api key for securing the vLLM models. Can be either:
# - A string containing the token directly (will be stored in a generated secret)
# - An object referencing an existing secret:
# secretName: "my-existing-secret"
# secretKey: "vllm-api-key"
#
# modelSpec - configuring multiple serving engines deployments that runs different models
# Each entry in the modelSpec array should contain the following fields:
# - name: (string) The name of the model, e.g., "example-model"
# - repository: (string) The repository of the model, e.g., "vllm/vllm-openai"
# - tag: (string) The tag of the model, e.g., "latest"
# - imagePullSecret: (Optional, string) Name of secret with credentials to private container repository, e.g. "secret"
# - modelURL: (string) The URL of the model, e.g., "facebook/opt-125m"
# - chatTemplate: (Optional, string) Chat template (Jinga2) specifying tokenizer configuration, e.g. "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ 'Question:\n' + message['content'] + '\n\n' }}{% elif message['role'] == 'system' %}\n{{ 'System:\n' + message['content'] + '\n\n' }}{% elif message['role'] == 'assistant' %}{{ 'Answer:\n' + message['content'] + '\n\n' }}{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ 'Answer:\n' }}{% endif %}{% endfor %}"
#
# - replicaCount: (int) The number of replicas for the model, e.g. 1
# - requestCPU: (int) The number of CPUs requested for the model, e.g. 6
# - requestMemory: (string) The amount of memory requested for the model, e.g., "16Gi"
# - requestGPU: (int) The number of GPUs requested for the model, e.g., 1
# - requestGPUType: (Optional, string) The type of GPU requested, e.g., "nvidia.com/mig-4g.71gb". If not specified, defaults to "nvidia.com/gpu"
# - limitCPU: (Optional, string) The CPU limit for the model, e.g., "8"
# - limitMemory: (Optional, string) The memory limit for the model, e.g., "32Gi"
# Note: If limitCPU and limitMemory are not specified, only GPU resources will have limits set equal to their requests.
# - pvcStorage: (Optional, string) The amount of storage requested for the model, e.g., "50Gi".
# - pvcAccessMode: (Optional, list) The access mode policy for the mounted volume, e.g., ["ReadWriteOnce"]
# - storageClass: (Optional, String) The storage class of the PVC e.g., "", default is ""
# - pvcMatchLabels: (Optional, map) The labels to match the PVC, e.g., {model: "opt125m"}
# - extraVolumes: (Optional, list) Additional volumes to add to the pod, in Kubernetes volume format. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#volume-v1-core
# Example for an emptyDir volume:
# extraVolumes:
# - name: tmp-volume
# emptyDir:
# medium: ""
# sizeLimit: 5Gi
# - extraVolumeMounts: (Optional, list) Additional volume mounts to add to the container, in Kubernetes volumeMount format. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#volumemount-v1-core
# Example for mounting the tmp-volume to /tmp:
# extraVolumeMounts:
# - name: tmp-volume
# mountPath: /tmp
# - initContainer: (optional, list of objects) The configuration for the init container to be run before the main container.
# - name: (string) The name of the init container, e.g., "init"
# - image: (string) The Docker image for the init container, e.g., "busybox:latest"
# - command: (optional, list) The command to run in the init container, e.g., ["sh", "-c"]
# - args: (optional, list) Additional arguments to pass to the command, e.g., ["ls"]
# - env: (optional, list) List of environment variables to set in the container, each being a map with:
# - resources: (optional, map) The resource requests and limits for the container:
# - mountPvcStorage: (optional, bool) Whether to mount the model's volume.
#
# - vllmConfig: (optional, map) The configuration for the VLLM model, supported options are:
# - enablePrefixCaching: (optional, bool) Enable prefix caching, e.g., false
# - enableChunkedPrefill: (optional, bool) Enable chunked prefill, e.g., false
# - maxModelLen: (optional, int) The maximum model length, e.g., 16384
# - dtype: (optional, string) The data type, e.g., "bfloat16"
# - tensorParallelSize: (optional, int) The degree of tensor parallelism, e.g., 2
# - maxNumSeqs: (optional, int) Maximum number of sequences to be processed in a single iteration., e.g., 32
# - maxLoras: (optional, int) The maximum number of LoRA models to be loaded in a single batch, e.g., 4
# - gpuMemoryUtilization: (optional, float) The fraction of GPU memory to be used for the model executor, which can range from 0 to 1. e.g., 0.95
# - extraArgs: (optional, list) Extra command line arguments to pass to vLLM, e.g., ["--disable-log-requests"]
#
# - lmcacheConfig: (optional, map) The configuration of the LMCache for KV offloading, supported options are:
# - enabled: (optional, bool) Enable LMCache, e.g., true
# - cpuOffloadingBufferSize: (optional, string) The CPU offloading buffer size, e.g., "30"
#
# - hf_token: (optional) Hugging Face token configuration. Can be either:
# - A string containing the token directly (will be stored in a generated secret)
# - An object referencing an existing secret:
# secretName: "my-existing-secret"
# secretKey: "hf-token-key"
#
# - env: (optional, list) The environment variables to set in the container, e.g., your HF_TOKEN
#
# - nodeSelectorTerms: (optional, list) The node selector terms to match the nodes
#
# - shmSize: (optional, string) The size of the shared memory, e.g., "20Gi"
#
# Example:
# vllmApiKey: "vllm_xxxxxxxxxxxxx"
# modelSpec:
# - name: "mistral"
# repository: "lmcache/vllm-openai"
# tag: "latest"
# modelURL: "mistralai/Mistral-7B-Instruct-v0.2"
# replicaCount: 1
#
# requestCPU: 10
# requestMemory: "64Gi"
# requestGPU: 1
#
# pvcStorage: "50Gi"
# pvcAccessMode:
# - ReadWriteOnce
# pvcMatchLabels:
# model: "mistral"
# initContainer:
# name: my-container
# image: busybox
# command: ["sh"]
# env: {}
# args: []
# resources: {}
# mountPvcStorage: true
#
# vllmConfig:
# enableChunkedPrefill: false
# enablePrefixCaching: false
# maxModelLen: 16384
# dtype: "bfloat16"
# maxNumSeqs: 32
# gpuMemoryUtilization: 0.95
# maxLoras: 4
# extraArgs: ["--disable-log-requests", "--trust-remote-code"]
#
# lmcacheConfig:
# enabled: true
# cpuOffloadingBufferSize: "30"
#
# hf_token: "hf_xxxxxxxxxxxxx"
#
#
# nodeSelectorTerms:
# - matchExpressions:
# - key: nvidia.com/gpu.product
# operator: "In"
# values:
# - "NVIDIA-RTX-A6000"
modelSpec: []
# -- Container port
containerPort: 8000
# -- Service port
servicePort: 80
# -- Set other environment variables from config map
configs: {}
# -- deployment strategy
strategy: {}
# -- Readiness probe configuration
startupProbe:
# -- Number of seconds after the container has started before startup probe is initiated
initialDelaySeconds: 15
# -- How often (in seconds) to perform the startup probe
periodSeconds: 10
# -- Number of times after which if a probe fails in a row, Kubernetes considers that the overall check has failed: the container is not ready
failureThreshold: 60
# -- Configuration of the Kubelet http request on the server
httpGet:
# -- Path to access on the HTTP server
path: /health
# -- Name or number of the port to access on the container, on which the server is listening
port: 8000
# -- Liveness probe configuration
livenessProbe:
# -- Number of seconds after the container has started before liveness probe is initiated
initialDelaySeconds: 15
# -- Number of times after which if a probe fails in a row, Kubernetes considers that the overall check has failed: the container is not alive
failureThreshold: 3
# -- How often (in seconds) to perform the liveness probe
periodSeconds: 10
# -- Configuration of the Kubelet http request on the server
httpGet:
# -- Path to access on the HTTP server
path: /health
# -- Name or number of the port to access on the container, on which the server is listening
port: 8000
# -- Disruption Budget Configuration
maxUnavailablePodDisruptionBudget: ""
# -- Tolerations configuration (when there are taints on nodes)
# Example:
# tolerations:
# - key: "node-role.kubernetes.io/control-plane"
# operator: "Exists"
# effect: "NoSchedule"
tolerations: []
# -- RuntimeClassName configuration, set to "nvidia" if the model requires GPU
runtimeClassName: "nvidia"
# -- SchedulerName configuration
schedulerName: ""
# -- Pod-level security context configuration. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#podsecuritycontext-v1-core
securityContext: {}
# -- Run as a non-root user ID
# runAsUser: 1000
# -- Run with a non-root group ID
# runAsGroup: 1000
# -- Run as non-root
# runAsNonRoot: true
# -- Set the seccomp profile
# seccompProfile:
# type: RuntimeDefault
# -- Drop all capabilities
# capabilities:
# drop:
# - ALL
# -- Set the file system group ID for all containers
# fsGroup: 1000
# -- Container-level security context configuration. https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.32/#securitycontext-v1-core
containerSecurityContext:
# -- Run as non-root
runAsNonRoot: false
# -- Don't allow privilege escalation
# allowPrivilegeEscalation: false
# -- Drop all capabilities
# capabilities:
# drop:
# - ALL
# -- Read-only root filesystem
# readOnlyRootFilesystem: true
routerSpec:
# -- The docker image of the router. The following values are defaults:
repository: "lmcache/lmstack-router"
tag: "latest"
imagePullPolicy: "Always"
# -- Whether to enable the router service
enableRouter: true
# -- Number of replicas
replicaCount: 1
# -- Container port
containerPort: 8000
# -- Service type
serviceType: ClusterIP
# -- Service port
servicePort: 80
# -- Service discovery mode, supports "k8s" or "static". Defaults to "k8s" if not set.
serviceDiscovery: "k8s"
# -- If serviceDiscovery is set to "static", the comma-separated values below are required. There needs to be the same number of backends and models
staticBackends: ""
staticModels: ""
# -- routing logic, could be "roundrobin" or "session"
routingLogic: "roundrobin"
# -- session key if using "session" routing logic
sessionKey: ""
# -- extra router commandline arguments
extraArgs: []
# -- Interval in seconds to scrape the serving engine metrics
engineScrapeInterval: 15
# -- Window size in seconds to calculate the request statistics
requestStatsWindow: 60
# -- deployment strategy
strategy: {}
# vllmApiKey: (optional) api key for securing the vLLM models. Must be an object referencing an existing secret
# secretName: "my-existing-secret"
# secretKey: "vllm-api-key"
# -- router resource requests and limits
resources:
requests:
cpu: "4"
memory: "16G"
limits:
cpu: "8"
memory: "32G"
# -- Customized labels for the router deployment
labels:
environment: "router"
release: "router"
ingress:
# -- Enable ingress controller resource
enabled: false
# -- IngressClass that will be used to implement the Ingress
className: ""
# -- Additional annotations for the Ingress resource
annotations: {}
# kubernetes.io/ingress.class: alb
# kubernetes.io/ingress.class: nginx
# kubernetes.io/tls-acme: "true"
# The list of hostnames to be covered with this ingress record.
hosts:
- host: vllm-router.local
paths:
- path: /
pathType: Prefix
# -- The tls configuration for hostnames to be covered with this ingress record.
tls: []
# - secretName: vllm-router-tls
# hosts:
# - vllm-router.local
# The node selector terms to match the nodes
# Example:
# nodeSelectorTerms:
# - matchExpressions:
# - key: nvidia.com/gpu.product
# operator: "In"
# values:
# - "NVIDIA-RTX-A6000"
nodeSelectorTerms: []
# -- TODO: Readiness probe configuration
#startupProbe:
# # -- Number of seconds after the container has started before startup probe is initiated
# initialDelaySeconds: 5
# # -- How often (in seconds) to perform the startup probe
# periodSeconds: 5
# # -- Number of times after which if a probe fails in a row, Kubernetes considers that the overall check has failed: the container is not ready
# failureThreshold: 100
# # -- Configuration of the Kubelet http request on the server
# httpGet:
# # -- Path to access on the HTTP server
#
Here is what this yaml settings has:
| Section | What It Means | Impact |
|---|---|---|
servingEngineSpec.enableEngine: true |
The vLLM serving engine will deploy | ✅ A model server (FastAPI/vLLM backend) will run |
servingEngineSpec.modelSpec: [] |
No models configured! | ❌ vLLM backend will start EMPTY, no model loaded, not usable |
servingEngineSpec.runtimeClassName: "nvidia" |
Requests GPU scheduling (runtimeClass = NVIDIA) | ⚠️ Will require GPU-capable nodes if enforced (Autopilot will handle automatically, but might error if none available) |
servingEngineSpec.containerPort: 8000, servicePort: 80 |
Internal pod listens on 8000; service listens on 80 | Standard setup for HTTP access inside cluster |
routerSpec.enableRouter: true |
The API router (proxy) will deploy | ✅ Will be able to route user traffic |
routerSpec.repository: lmcache/lmstack-router, tag: latest |
Uses default router Docker image | Fine, but might pull latest, unstable sometimes |
routerSpec.serviceType: ClusterIP |
Router is only internally reachable | ❗ No public IP, need port-forward or LoadBalancer later if needed |
routerSpec.routingLogic: roundrobin |
Router sends requests evenly across backends | Good for simple load balancing |
routerSpec.resources.requests: {cpu: "4", memory: "16G"} |
Router will reserve 4 CPU cores and 16Gi RAM minimum | 🏋️ Heavy for tiny clusters; fine for prod-scale |
I found that I could test it using only 1 pod with gpu
Open api port on runpod
8001is used by nginx, lets use 8002
# Serve on port 8002 instead:
vllm serve --task transcription openai/whisper-small \
--host 0.0.0.0 --port 8002
# if success , you will get this log
# (workspace) root@33e3bb091952:/workspace/production-stack# vllm serve --task transcription openai/whisper-small --host 0.0.0.0 --port 8002
# INFO 05-29 21:52:43 [__init__.py:243] Automatically detected platform cuda.
# INFO 05-29 21:52:59 [__init__.py:31] Available plugins for group vllm.general_plugins:
# INFO 05-29 21:52:59 [__init__.py:33] - lora_filesystem_resolver -> vllm.plugins.lora_resolvers.filesystem_resolver:register_filesystem_resolver
# INFO 05-29 21:52:59 [__init__.py:36] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load.
# INFO 05-29 21:53:01 [api_server.py:1289] vLLM API server version 0.9.0
# INFO 05-29 21:53:02 [cli_args.py:300] non-default args: {'host': '0.0.0.0', 'port': 8002, 'task': 'transcription'}
# config.json: 100%|███████████████████████████████████████████████████████████| 1.97k/1.97k [00:00<00:00, 11.5MB/s]
# preprocessor_config.json: 100%|████████████████████████████████████████████████| 185k/185k [00:00<00:00, 4.46MB/s]
# INFO 05-29 21:53:03 [config.py:3131] Downcasting torch.float32 to torch.float16.
# WARNING 05-29 21:53:30 [arg_utils.py:1583] --task transcription is not supported by the V1 Engine. Falling back to V0.
# INFO 05-29 21:53:46 [__init__.py:243] Automatically detected platform cuda.
# INFO 05-29 21:53:54 [api_server.py:257] Started engine process with PID 9035
# INFO 05-29 21:53:54 [__init__.py:31] Available plugins for group vllm.general_plugins:
# INFO 05-29 21:53:54 [__init__.py:33] - lora_filesystem_resolver -> vllm.plugins.lora_resolvers.filesystem_resolver:register_filesystem_resolver
# INFO 05-29 21:53:54 [__init__.py:36] All plugins in this group will be loaded. Set `VLLM_PLUGINS` to control which plugins to load.
# INFO 05-29 21:53:54 [llm_engine.py:230] Initializing a V0 LLM engine (v0.9.0) with config: model='openai/whisper-small', speculative_config=None, tokenizer='openai/whisper-small', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config={}, tokenizer_revision=None, trust_remote_code=False, dtype=torch.float16, max_seq_len=448, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend=''), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=openai/whisper-small, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=None, chunked_prefill_enabled=False, use_async_output_proc=True, pooler_config=None, compilation_config={"compile_sizes": [], "inductor_compile_config": {"enable_auto_functionalized_v2": false}, "cudagraph_capture_sizes": [256, 248, 240, 232, 224, 216, 208, 200, 192, 184, 176, 168, 160, 152, 144, 136, 128, 120, 112, 104, 96, 88, 80, 72, 64, 56, 48, 40, 32, 24, 16, 8, 4, 2, 1], "max_capture_size": 256}, use_cached_outputs=True,
# tokenizer_config.json: 100%|███████████████████████████████████████████████████| 283k/283k [00:00<00:00, 4.41MB/s]
# vocab.json: 100%|██████████████████████████████████████████████████████████████| 836k/836k [00:00<00:00, 33.2MB/s]
# tokenizer.json: 100%|████████████████████████████████████████████████████████| 2.48M/2.48M [00:00<00:00, 31.7MB/s]
# merges.txt: 100%|██████████████████████████████████████████████████████████████| 494k/494k [00:00<00:00, 14.5MB/s]
# normalizer.json: 100%|████████████████████████████████████████████████████████| 52.7k/52.7k [00:00<00:00, 242MB/s]
# added_tokens.json: 100%|██████████████████████████████████████████████████████| 34.6k/34.6k [00:00<00:00, 203MB/s]
# special_tokens_map.json: 100%|███████████████████████████████████████████████| 2.19k/2.19k [00:00<00:00, 34.0MB/s]
# generation_config.json: 100%|████████████████████████████████████████████████| 3.87k/3.87k [00:00<00:00, 48.9MB/s]
# INFO 05-29 21:53:55 [cuda.py:292] Using Flash Attention backend.
# INFO 05-29 21:53:56 [parallel_state.py:1064] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
# INFO 05-29 21:53:56 [model_runner.py:1170] Starting to load model openai/whisper-small...
# INFO 05-29 21:53:57 [weight_utils.py:291] Using model weights format ['*.safetensors']
# model.safetensors: 100%|████████████████████████████████████████████████████████| 967M/967M [00:03<00:00, 294MB/s]
# INFO 05-29 21:54:01 [weight_utils.py:307] Time spent downloading weights for openai/whisper-small: 3.485868 seconds
# INFO 05-29 21:54:01 [weight_utils.py:344] No model.safetensors.index.json found in remote.
# Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
# Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 4.22it/s]
# Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 4.22it/s]
#
# INFO 05-29 21:54:01 [default_loader.py:280] Loading weights took 0.28 seconds
# INFO 05-29 21:54:01 [model_runner.py:1202] Model loading took 0.4668 GiB and 5.083266 seconds
# INFO 05-29 21:54:03 [enc_dec_model_runner.py:315] Starting profile run for multi-modal models.
# INFO 05-29 21:54:07 [worker.py:291] Memory profiling takes 5.44 seconds
# INFO 05-29 21:54:07 [worker.py:291] the current vLLM instance can use total_gpu_memory (23.54GiB) x gpu_memory_utilization (0.90) = 21.19GiB
# INFO 05-29 21:54:07 [worker.py:291] model weights take 0.47GiB; non_torch_memory takes 0.08GiB; PyTorch activation peak memory takes 6.29GiB; the rest of the memory reserved for KV Cache is 14.35GiB.
# INFO 05-29 21:54:07 [executor_base.py:112] # cuda blocks: 26125, # CPU blocks: 7281
# INFO 05-29 21:54:07 [executor_base.py:117] Maximum concurrency for 448 tokens per request: 933.04x
# INFO 05-29 21:54:12 [model_runner.py:1512] Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
# Capturing CUDA graph shapes: 100%|████████████████████████████████████████████████| 35/35 [00:15<00:00, 2.22it/s]
# INFO 05-29 21:54:27 [model_runner.py:1670] Graph capturing finished in 16 secs, took 0.15 GiB
# INFO 05-29 21:54:27 [llm_engine.py:428] init engine (profile, create kv cache, warmup model) took 25.88 seconds
# INFO 05-29 21:54:29 [api_server.py:1336] Starting vLLM API server on http://0.0.0.0:8002
# INFO 05-29 21:54:29 [launcher.py:28] Available routes are:
# INFO 05-29 21:54:29 [launcher.py:36] Route: /openapi.json, Methods: HEAD, GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /docs, Methods: HEAD, GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: HEAD, GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /redoc, Methods: HEAD, GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /health, Methods: GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /load, Methods: GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /ping, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /ping, Methods: GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /tokenize, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /detokenize, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/models, Methods: GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /version, Methods: GET
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/completions, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/embeddings, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /pooling, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /classify, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /score, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/score, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /rerank, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v1/rerank, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /v2/rerank, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /invocations, Methods: POST
# INFO 05-29 21:54:29 [launcher.py:36] Route: /metrics, Methods: GET
# INFO: Started server process [8831]
# INFO: Waiting for application startup.
# INFO: Application startup complete.
# And update your router to point there:
export VLLM_BACKEND_URL="http://localhost:8002"
uvicorn main_router:app --reload --port 8000
also run the production stacks
Good thing we’ve the consistent python env, we can set the PYTHONPATH
also install the dependencies for production-stack in editable mode
source /workspace/.venv/bin/activate
pip install -e /workspace/production-stack[dev]
[!NOTE] production-stack need python 3.12, let’s use a python 3.12 venv
If you faced no space while installing, move cache to workspace
export PIP_CACHE_DIR=/workspace/.pip_cache
mkdir -p /workspace/.pip_cache
pip cache purge # clear the old cache on overlay
pip install vllm[audio]
pip install -e production-stack[dev]
If there’s no pip locally, install the pip
(workspace) root@33e3bb091952:/workspace# which pip
/usr/local/bin/pip
(workspace) root@33e3bb091952:/workspace# python -m pip install --upgrade pip setuptools
/workspace/.venv/bin/python: No module named pip
(workspace) root@33e3bb091952:/workspace# ls .venv/
CACHEDIR.TAG bin lib lib64 pyvenv.cfg
(workspace) root@33e3bb091952:/workspace# ls .venv/bin
activate activate.csh activate.nu activate_this.py pydoc.bat python3
activate.bat activate.fish activate.ps1 deactivate.bat python python3.12
(workspace) root@33e3bb091952:/workspace# python -m ensurepip --upgrade
Looking in links: /tmp/tmp8w8h4iwe
Processing /tmp/tmp8w8h4iwe/pip-23.2.1-py3-none-any.whl
Installing collected packages: pip
Successfully installed pip-23.2.1
Install vLLM (with audio) without filling the small overlay cache
export PIP_NO_CACHE_DIR=1
pip install vllm[audio]
Install router in editable mode
pip install -e production-stack[dev]
verify both are installed under python3.12
pip list | grep -E "vllm|vllm-router"
# (workspace) root@33e3bb091952:/workspace# pip list | grep -E "vllm|vllm-router"
# vllm 0.9.0
Testing script
- start the whisper backend
vllm serve --task transcription openai/whisper-small \
--host 0.0.0.0 --port 8002
- Started the production-stack router (your main_router on port 8000), for example with:
- add this to
src/vllm_router/run-router.shand comment other router services for testing
# Use this command when testing with whisper transcription
ROUTER_PORT=$1
BACKEND_URL=$2
python3 -m vllm_router.app \
--host 0.0.0.0 \
--port "${ROUTER_PORT}" \
--service-discovery static \
--static-backends "${BACKEND_URL}" \
--static-models "openai/whisper-small" \
--static-model-types "transcription" \
--routing-logic roundrobin \
--log-stats \
--engine-stats-interval 10 \
--request-stats-window 10
# To disable this warning, you can either:
# - Avoid using `tokenizers` before the fork if possible
# - Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
# INFO 05-29 23:29:15 [api_server.py:1336] Starting vLLM API server on http://0.0.0.0:8002
# INFO 05-29 23:29:15 [launcher.py:28] Available routes are:
# INFO 05-29 23:29:15 [launcher.py:36] Route: /openapi.json, Methods: HEAD, GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /docs, Methods: HEAD, GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /docs/oauth2-redirect, Methods: HEAD, GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /redoc, Methods: HEAD, GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /health, Methods: GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /load, Methods: GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /ping, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /ping, Methods: GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /tokenize, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /detokenize, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/models, Methods: GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /version, Methods: GET
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/chat/completions, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/completions, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/embeddings, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /pooling, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /classify, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /score, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/score, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/audio/transcriptions, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /rerank, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v1/rerank, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /v2/rerank, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /invocations, Methods: POST
# INFO 05-29 23:29:15 [launcher.py:36] Route: /metrics, Methods: GET
# INFO: Started server process [9747]
# INFO: Waiting for application startup.
# INFO: Application startup complete.
# INFO: 127.0.0.1:46250 - "GET /metrics HTTP/1.1" 200 OK
- make sure make it executable
(workspace) root@33e3bb091952:/workspace/production-stack# cd src/vllm_router
(workspace) root@33e3bb091952:/workspace/production-stack# chmod +x run-router.sh
(workspace) root@33e3bb091952:/workspace/production-stack# ./run-router.sh 8000
(workspace) root@33e3bb091952:/workspace/production-stack/src/vllm_router# ./run-router.sh 8000
# [2025-05-29 23:30:44,964] INFO: Scraping metrics from 1 serving engine(s) (engine_stats.py:136:vllm_router.stats.engine_stats)
# [2025-05-29 23:30:44,964] INFO: Initializing round-robin routing logic (routing_logic.py:392:vllm_router.routers.routing_logic)
# INFO: Started server process [10309]
# INFO: Waiting for application startup.
# [2025-05-29 23:30:45,089] INFO: httpx AsyncClient instantiated. Id 140322398720160 (httpx_client.py:31:vllm_router.httpx_client)
# INFO: Application startup complete.
# INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
# [2025-05-29 23:30:54,965] INFO:
# ==================================================
# Server: http://localhost:8002
# Models:
# - openai/whisper-small
# Engine Stats: Running Requests: 0.0, Queued Requests: 0.0, GPU Cache Hit Rate: 0.00
# Request Stats: No stats available
# --------------------------------------------------
# ==================================================
# (log_stats.py:104:vllm_router.stats.log_stats)
# [2025-05-29 23:30:54,984] INFO: Scraping metrics from 1 serving engine(s) (engine_stats.py:136:vllm_router.stats.engine_stats)
# [2025-05-29 23:31:04,966] INFO:
# ==================================================
# Server: http://localhost:8002
# Models:
# - openai/whisper-small
# Engine Stats: Running Requests: 0.0, Queued Requests: 0.0, GPU Cache Hit Rate: 0.00
# Request Stats: No stats available
# --------------------------------------------------
# ==================================================
# (log_stats.py:104:vllm_router.stats.log_stats)
# [2025-05-29 23:31:04,991] INFO: Scraping metrics from 1 serving engine(s) (engine_stats.py:136:vllm_router.stats.engine_stats)
# [2025-05-29 23:31:14,966] INFO:
# ==================================================
# Server: http://localhost:8002
# Models:
# - openai/whisper-small
# Engine Stats: Running Requests: 0.0, Queued Requests: 0.0, GPU Cache Hit Rate: 0.00
# Request Stats: No stats available
# --------------------------------------------------
# ==================================================
# (log_stats.py:104:vllm_router.stats.log_stats)
# [2025-05-29 23:31:14,997] INFO: Scraping metrics from 1 serving engine(s) (engine_stats.py:136:vllm_router.stats.engine_stats)
# [2025-05-29 23:31:24,967] INFO:
# ==================================================
# Server: http://localhost:8002
# Models:
# - openai/whisper-small
# Engine Stats: Running Requests: 0.0, Queued Requests: 0.0, GPU Cache Hit Rate: 0.00
# Request Stats: No stats available
# --------------------------------------------------
# ==================================================
# (log_stats.py:104:vllm_router.stats.log_stats)
# [2025-05-29 23:31:25,004] INFO: Scraping metrics from 1 serving engine(s) (engine_stats.py:136:vllm_router.stats.engine_stats)
- smoke test the transcription endpoint
curl -v http://localhost:8000/v1/audio/transcriptions \
-F 'file=@/path/to/audio.wav;type=audio/wav' \
-F 'model=whisper-small' \
-F 'language=en'
[!NOTE] Record an input audio before testing
Implementation Details
Enabling the transcription model type
Add a new enum member in utils.py so the parser recognizes transcription as a valid model type:
class ModelType(enum.Enum):
…
transcription = "/v1/audio/transcriptions"
Then include it in your get_all_fields() so validate_static_model_types() accepts it .
Parser validation
Update validate_static_model_types in parsers/parser.py to allow the new transcription string:
def validate_static_model_types(model_types: str | None) -> None:
…
all_models = utils.ModelType.get_all_fields()
# now includes 'transcription'
This ensures --static-model-types transcription passes validation .
Main router proxy logic
In routers/main_router.py’s audio_transcriptions handler, use the same service‐discovery + routing logic you already have for chat/completions, but:
- Filter by
model_label=="transcription"(or skip it in dev) andmodel in ep.model_names. - Increase HTTPX timeout, since Whisper can take a while:
async with httpx.AsyncClient(
base_url=chosen_url,
timeout=httpx.Timeout(connect=5, read=120, write=30, pool=None)
) as client:
…
- Proxy the multipart form exactly to /v1/audio/transcriptions on the backend .
Smoke-Testing
- Start the Whisper backend on port 8002:
vllm serve --task transcription openai/whisper-small \
--host 0.0.0.0 --port 8002
- run the modified router on port 8000:
./run-router.sh 8000 http://localhost:8002
- hit the endpoint with
curl, noting you must specify a validresponse_format(e.g.json):
curl -v http://localhost:8000/v1/audio/transcriptions \
-F 'file=@/path/to/audio.wav;type=audio/wav' \
-F 'model=openai/whisper-small' \
-F 'response_format=json' \
-F 'language=en'
- Finally, you should get back something like:
{"text":"…your transcription…"}
which confirms end-to-end routing.
Troubleshooting & Tips
-
“No transcription backend” 503 Means your router didn’t detect any backend with
model_label=="transcription". Double-check--static-model-labels transcriptionor skip the label filter in dev. -
Timeouts If you see
ReadTimeout, bump upreadinhttpx.Timeout(...). -
Response format errors Whisper only accepts one of
json,text,srt,verbose_json,vttforresponse_format.