Vllm V1 Whisper Transcription
In this blog I’ll refine my work process for the whisper transcription api implementation , as a support material for transcription api endpoint pr, here are step by step how I did it
Create a GPU environment
- I use Runpod.io for renting a RTX4090.
- You will get ssh access when initialize a pod.
- Some trails and errors details can reference Deploying LLMs in a single Machine
Clone the repo, Setup python environment with uv
cd workspace/ # workspace has the largest size
apt update && apt upgrade
curl -LsSf https://astral.sh/uv/install.sh | sh
export PATH="$HOME/.local/bin:$PATH"
source ~/.bashrc
Then you can use uv
[!NOTE] For production-stack repo we need python 3.12
git clone https://github.com/davidgao7/production-stack.git
cd production-stack
[!NOTE] Pay attention to your runpod cuda and pytorch version
runpod/pytorch:2.1.0-py3.10-cuda11.8.0-devel-ubuntu22.04
uv venv --python 3.12 --seed
source .venv/bin/activate
Install the dependencies
which pip # make sure the pip you are using is the venv one
pip install -e /workspace/production-stack[dev]
If you face this issue, I recommend you to build vllm from repo source too:
# --- Part A: Create the Python 3.12 Environment ---
echo "--- Creating a fresh Python 3.12 environment ---"
cd /workspace/production-stack
# Remove any old virtual environments to be safe
rm -rf .venv*
# Create a venv using the Python 3.12 we just installed
uv venv --python 3.12
# Activate it
source .venv/bin/activate
# you can setting a TMPDIR to make sure vllm build won't crash
mkdir -p /workspace/build_temp
# export TMPDIR=/workspace/build_temp
# --- Part B: Install Build Tools & Correct PyTorch ---
echo "--- Installing build tools and PyTorch for CUDA 12.x ---"
# Install cmake (if not already present) and upgrade pip
apt-get install -y cmake
TMPDIR=/workspace/build_temp uv pip install --upgrade pip
# Install the PyTorch version that matches your system's CUDA driver
TMPDIR=/workspace/build_temp uv pip install torch torchvision torchaudio
# --- Part C: Build vLLM from Source with Audio Support ---
echo "--- Building vLLM from source, this will take several minutes ---"
# MAX_JOBS=1 is a safeguard to prevent the compiler from crashing due to low RAM
# --no-cache-dir ensures a completely fresh build
# MAX_JOBS=1 pip install --no-cache-dir "vllm[audio] @ git+https://github.com/vllm-project/vllm.git"
# Export the correct GPU architecture for your RTX 4090
# export VLLM_CUDA_ARCHES=89 # this number represents RTX4090
VLLM_CUDA_ARCHES=89 MAX_JOBS=1 TMPDIR=/workspace/build_temp uv pip install --no-cache-dir "vllm[audio] @ git+https://github.com/vllm-project/vllm.git"
# if build too long, you can just try `MAX_JOBS=1 uv pip install --no-cache-dir "vllm[audio]" `
# --- Part D: Install Your Project ---
echo "--- Installing your production-stack project ---"
# This will now work because your environment is Python 3.12
TMPDIR=/workspace/build_temp uv pip install -e .[dev]
# --- FINAL STEP ---
echo "✅ Environment setup complete. You are now ready to start the vLLM server."
Wait till it finishes, it will take a while to download the dependencies.
Install vLLM (with audio) without filling the small overlay cache
Compiling large C++/CUDA codebases is a very memory-intensive process. By default, the build system tries to use all available CPU cores to compile files in parallel (e.g., you might see -j=32 in the logs, meaning 32 parallel jobs). On a machine with limited RAM, this can easily exhaust all available memory and cause the compiler to segfault.
Install dependencies into a large volume:
# df -h
MAX_JOBS=1 uv pip install --no-cache-dir "vllm[audio] @ git+https://github.com/vllm-project/vllm.git" --target=/path/to/your/directory
MAX_JOBS=1 pip install --no-cache-dir "vllm[audio] @ git+https://github.com/vllm-project/vllm.git"
[!NOTE] If you have cuda and build failed, use uv pip install
MAX_JOBS=1 uv pip install --no-cache-dir "vllm[audio] @ git+https://github.com/vllm-project/vllm.git"
Verify you have both vllm and vllm-router installed
uv pip list | grep -E "vllm|vllm-router"
Code implementation snippet
In production-stack repo
- Main router implementation pit I fell before: src/vllm_router/routers/main_router.py/async def audio_transcriptions
- File upload for fastapi
- Filter endpoint urls for transcription as the start url
- Pick one of the endpoint url using
router.route_request - Proxy the request with
httpx.AsyncClient - Get the whisper model output
@main_router.post("/v1/audio/transcriptions")
async def audio_transcriptions(
file: UploadFile = File(...)
model: str = Form(...),
prompt: str | None = Form(None),
response_format: str | None = Form("json"),
temperature: float | None = Form(None),
language: str = Form("en"),
):
# filter url for audio transcription endpoints
transcription_endpoints = [ep for ep in endpoints if model == ep.model_name]
# pick one using the router's configured logic (roundrobin, least-loaded, etc.)
chosen_url = router.route_request(
transcription_endpoints,
engine_stats,
request_stats,
# we don’t need to pass the original FastAPI Request object here,
# but you can if your routing logic looks at headers or body
None,
)
# ...
# proxy the request
# by default httpx will only wait for 5 seconds, large audio transcriptions generally
# take longer than that
async with httpx.AsyncClient(
base_url=chosen_url,
timeout=httpx.Timeout(
connect=60.0, # connect timeout
read=300.0, # read timeout
write=30.0, # if you’re streaming uploads
pool=None, # no pool timeout
),
) as client:
logger.debug("Sending multipart to %s/v1/audio/transcriptions …", chosen_url)
proxied = await client.post("/v1/audio/transcriptions", data=data, files=files)
-
Make sure input is a wav audio file.
-
Adding model type: src/vllm_router/utils.py
class ModelType(enum.Enum):
#...
transcription = "/v1/audio/transcriptions"
@staticmethod
def get_test_payload(model_type: str):
match ModelType[model_type]:
# ...
case ModelType.transcription:
return {
"file": "",
"model": "openai/whisper-small"
}
Testing
-
create a shell script to take
router port,backend_url, spin up the vllm api endpoint -
command to serve the model engine
# vllm backend serve on port 8002:
uv run vllm serve --task transcription openai/whisper-small --host 0.0.0.0 --port 8002 --trust-remote-code
if face ImportError: libcudart.so.12: cannot open shared object file: No such file or directory, expose the cuda library path
LD_LIBRARY_PATH=/usr/local/cuda/lib64 uv run vllm serve --task transcription openai/whisper-small --host 0.0.0.0 --port 8002 --trust-remote-code
[!NOTE] vllm process won’t die when you stop it, you can kill -9 the process
no wonder I always got no resoruces in pod… oof
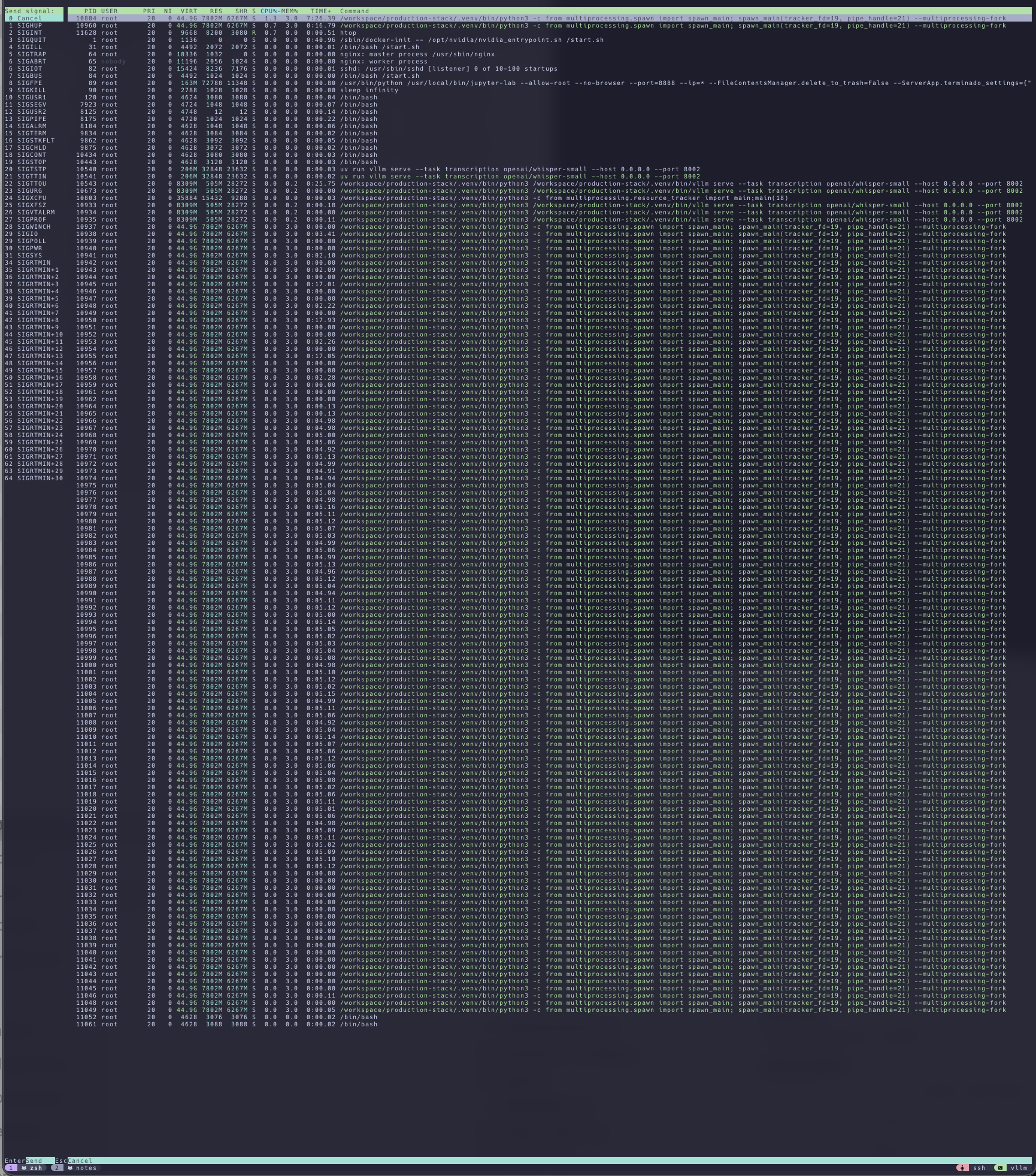
kill all the vllm processes
pkill -f "vllm serve"
or kill by python path (more board)
pkill -f "/workspace/production-stack/.venv/bin/python3"
- command to run the router, connect to the backend
#!/bin/bash
if [[ $# -ne 2 ]]; then
echo "Usage $0 <router port> <backend url>"
exit 1
fi
# router serve on port 8000, connect to the vllm backend on port 8002:
uv run python3 -m vllm_router.app \
--host 0.0.0.0 --port 8000 \
--service-discovery static \
--static-backends "http://0.0.0.0:8002" \
--static-models "openai/whisper-small" \
--static-model-labels "transcription" \
--routing-logic roundrobin \
--log-stats \
--log-level debug \ # log level: "debug", "info", "warning", "error", "critical"
--engine-stats-interval 10 \
--request-stats-window 10
--static-backend-health-checks # Enable this flag to make vllm-router check periodically if the models work by sending dummy requests to their endpoints.
- You can set the logging level to display different level’s logging output.
Note that the port for --static-backends is the port you set for the vllm serve command, in this case 8002.
Then wait till it’s listen on the port, you can post an audio file to the endpoint, for example
- command to get the transcription result as json by using
curl
# when calling the endpoint, make sure the file is a wav audio file
curl -v http://localhost:8002/v1/audio/transcriptions \
-F 'file=@/workspace/production-stack/src/vllm_router/audio_transcriptions_test.wav;type=audio/wav' \
-F 'model=openai/whisper-small' \
-F 'response_format=json' \
-F 'language=en'
Handling empty(no) audio file request
# one of the match case in python switch statement
case ModelType.transcription:
# Generate a 0.1 second silent audio file
with io.BytesIO() as wav_buffer:
with wave.open(wav_buffer, "wb") as wf:
wf.setnchannels(1) # mono audio channel, standard configuration
wf.setsampwidth(2) # 16 bit audio, common bit depth for wav file
wf.setframerate(16000) # 16 kHz sample rate
wf.writeframes(b"\x00\x00" * 1600) # 0.1 second of silence
# retrieves the generated wav bytes, return
wav_bytes = wav_buffer.getvalue()
return {
"file": ("empty.wav", wav_bytes, "audio/wav"),
}
Log for running vllm backend
In the test audio file, I said: “Testing testing, testing the whisper small model; testing testing, testing the audio transcription function; testing testing, testing the whisper small model.”
INFO 06-01 10:51:27 [logger.py:39] Received request trsc-310b30730a4a433d9d9c84437206579c: prompt: '<|startoftranscript|><|en|><|transcribe|><|notimestamps|>', params: SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.0, temperature=0.0, top_p=1.0, top_k=-1, min_p=0.0, seed=None, stop=[], stop_token_ids=[], bad_words=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=448, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None, guided_decoding=None, extra_args=None), prompt_token_ids: None, lora_request: None, prompt_adapter_request: None.
INFO 06-01 10:51:27 [engine.py:310] Added request trsc-310b30730a4a433d9d9c84437206579c.
INFO 06-01 10:51:27 [metrics.py:481] Avg prompt throughput: 0.5 tokens/s, Avg generation throughput: 0.1 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.4%, CPU KV cache usage: 0.0%.
INFO: 127.0.0.1:41532 - "POST /v1/audio/transcriptions HTTP/1.1" 200 OK
INFO 06-01 10:51:37 [metrics.py:481] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 1.8 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 06-01 10:51:47 [metrics.py:481] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
And this is debug output, shows it hits my code:
Log for running vllm router
==================================================
Server: http://localhost:8002
Models:
- openai/whisper-small
Engine Stats: Running Requests: 0.0, Queued Requests: 0.0, GPU Cache Hit Rate: 0.00
Request Stats: No stats available
--------------------------------------------------
==================================================
(log_stats.py:104:vllm_router.stats.log_stats)
[2025-05-30 05:58:36,809] INFO: Scraping metrics from 1 serving engine(s) (engine_stats.py:136:vllm_router.stats.engine_stats)
[2025-05-30 05:58:43,042] INFO: Received 200 from whisper backend (main_router.py:293:vllm_router.routers.main_router)
[2025-05-30 05:58:43,042] DEBUG: ==== Whisper response payload ==== (main_router.py:298:vllm_router.routers.main_router)
[2025-05-30 05:58:43,042] DEBUG: {'text': ' Testing testing testing the whisper small model testing testing testing the audio transcription function testing testing testing the whisper small model'} (main_router.py:299:vllm_router.routers.main_router)
[2025-05-30 05:58:43,042] DEBUG: ==== Whisper response payload ==== (main_router.py:300:vllm_router.routers.main_router)
[2025-05-30 05:58:43,042] DEBUG: Backend response headers: Headers({'date': 'Fri, 30 May 2025 05:58:31 GMT', 'server': 'uvicorn', 'content-length': '164', 'content-type': 'application/json'}) (main_router.py:302:vllm_router.routers.main_router)
[2025-05-30 05:58:43,042] DEBUG: Backend response body (truncated): b'{"text":" Testing testing testing the whisper small model testing testing testing the audio transcription function testing testing testing the whisper small model"}' (main_router.py:303:vllm_router.routers.main_router)
INFO: 127.0.0.1:49284 - "POST /v1/audio/transcriptions HTTP/1.1" 200 OK
[2025-05-30 05:58:46,769] INFO:
Log/result of the posting (curl command)
* Trying 127.0.0.1:8002...
* Connected to localhost (127.0.0.1) port 8002 (#0)
> POST /v1/audio/transcriptions HTTP/1.1
> Host: localhost:8002
> User-Agent: curl/7.81.0
> Accept: */*
> Content-Length: 1275490
> Content-Type: multipart/form-data; boundary=------------------------058cd4e05f99b8bc
> Expect: 100-continue
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 100 Continue
* We are completely uploaded and fine
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< date: Sun, 01 Jun 2025 10:51:27 GMT
< server: uvicorn
< content-length: 80
< content-type: application/json
<
* Connection #0 to host localhost left intact
{"text":" Testing testing testing the whisper small model testing testing testing the audio transcription function testing testing testing the whisper small model"}
The “clean” output of the transcription is, in json format:
{
"text":" Testing testing testing the whisper small model testing testing testing the audio transcription function testing testing testing the whisper small model"
}
Which is what I said in the audio file.
This conclude that the whisper transcription api endpoint is working as expected.